

In the series: How the Internet Works Series
Introduction
Part One of this module series explains the address system used to transmit messages across the Internet. Many modern programs and apps send information over the Internet, and in return many libraries and APIs have tools devoted to that use. Unfortunately, these interfaces are designed for coders who already know how the internet works, and there are few resources to fill in the missing details for those who are unfamiliar with these ideas.
The main objective of this module is to examine the types of addresses students will interact with as Internet coders: MAC, IP, port, and URL. The OSI model for the Internet will be introduced as a necessary prerequisite for the address system, which will also help students learn to how to diagnose basic connection problems.
This module aligns with a Computer Studies curriculum as it teaches the fundamentals of how to navigate the internet using established protocols. In doing so, it builds students digital skills and comfort in an online environment, allowing them to search more efficiently for all projects and subjects they pursue.
Some Questions to Ask Yourself
- What is The Cloud? How does it work?
- What’s the difference between HTTP and HTTPS?
- How can you connect to a friend’s laptop? Is that related to the Internet?
The computer activities in this module use the Ubuntu terminal to explore MAC, IP, and URL addresses. Specific command line tools include ip, man, ping, grep, traceroute, whois, ssh, scp.
How Does the Internet Work?
The Internet. We use it every day, in all sorts of ways. We take for granted that it works, but how does it work? And why does it work the way it does?
The Internet is a sophisticated communications technology. It is The Cloud. It is the keeper of our favorite apps, memes, photos, and messages. It is also more than just these things: the Internet has changed the way humans communicate, and in return has changed our collective behaviours. If you want to fully understand the Internet, there is a social aspect that needs to be learned – something which many people take for granted.
Part One of this module series looks at the technical side of how the Internet works. It offers a perspective for troubleshooting problems that may arise during online interactions. Such a skill set provides a good basis from which to learn about other internet technologies built on these foundations. Furthermore, it provides a grounded understanding of the human side of the Internet which is explored in Part Two.
Learning Style
How do you learn? I will explain my way:
Ikiaqqijjut, the tool to travel through layers.
In the days of Inuit Angakkuit, ikiaqqijjut was the process shamans used to communicate with others across long distances. The idea is that shamans would enter a trance, and while in this trance they would travel through spiritual layers to visit any part of the world. It is how they could visit family from a distance. Sound familiar? Eva Aariak, who at the time was a Languages Commissioner of Nunavut, chose this Inuktitut word and extended its meaning: Ikkiaqqijjut now means Internet.
How do I learn? I try to memorize as many details as I can, to keep my mind sharp and strong. I memorize details by turning them into stories, and then build relationships between these stories to find a deeper meaning. Yet, for all my memorizing and knowledge building, I realize that the sum of all human knowledge is far more than I can fit in my brain.
I also learn with the help of memory devices, which offer a platform to acquire even more. My mind is such a device, and the Internet is another. In this place of great memory I can find interesting things I would not have considered or predicted on my own. I can learn new stories and new relationships. It is an amazing thing.
Points of Focus
I also learn by finding points of focus, or places to return to when things get confusing.
Often I seek out a meaningful word as a point of focus. If I can find a word which connects many of the ideas I’m learning about; a word that keeps recurring; then I can use it to learn new perspectives and improve my understanding even further.
For example, when thinking about the technical side of the Internet, it all comes down to being able to send messages. It’s not about the content of the message, or what people do with them, it’s about the idea of transmission. In this module the word transmission is such a point of focus.
These are my ways of learning. What are yours?
Engineering
The Internet was designed by engineers. Does this mean we have to be engineers to understand the Internet? Nope, not at all!
Stratification
A big part of engineering is about asking an important question: what could go wrong? When engineers design things, they make sure to protect against things that could go wrong. The solutions for these sorts of problems are called mitigation strategies. To say this another way: engineers simplify and break down their designs so they can minimize things that could go wrong.
Now that we know about mitigation, how do we mitigate against all the problems that might arise during an internet transmission? By using a technique called stratification. The idea is to break a transmission into layers of simpler transmissions. For example, the postal system uses a hierarchy of addresses; that’s a stratification design.
How are internet transmissions stratified? We start with the closest and most obvious transmissions, and work outward from there. When it comes to the Internet the closest, most obvious transmission is sending a message between two devices that are directly connected to each other. If we can do this much, then we call this the first layer, and build the next layer on top of it. Each layer built this way makes use of the previous layer, but is otherwise independent.
If you’re using a stratification strategy in your design, or trying to understand someone else’s stratification designs, it’s a good habit to ask the following questions for each layer:
- What’s possible?
- What’s practical?
It can give you an understanding for why the layer exists, which is especially useful if the layer seems confusing or complicated.
Specification
Another aspect of engineering is the idea of a specification, or spec (pronounced “spek”) for short. A spec is kind of like a legal document, but for engineers. It helps them establish expectations when planning and implementing. This is especially useful for large projects with many people as it helps maintain agreement and prevents unpleasant surprises.
What about the Internet, does it have a spec? It does! There is more than one, in fact, but we’ll introduce the most common one known as The Open Systems Interconnection (OSI) model. It is very technical so we won’t get into the details, but the basics are a major focus of this module.
Snail Mail and Traffic Jams
How would I describe the Internet? It is like nothing else.
Even still, sometimes it helps to compare it to other things – things we already understand. Before we begin our journey through the layers of the OSI model, there are two analogies worth discussing to help us to better understand transmissions:
- The Postal System
- Transportation Networks
When a transmission works well, it’s a bit like the postal system. The post office transports our packages fairly reliably, as long as the address is clear and follows an established pattern.
The Internet works in a similar way: when messages are transmitted, the address is arranged in a hierarchy, which is followed to get them to their destination. The main difference is that these internet addresses are usually hidden from regular users. We’ll learn how that works later.
When a transmission doesn’t work well, and gets stuck, delayed, and otherwise doesn’t reach its destination smoothly, it’s more like a traffic jam or getting stuck at a train crossing, waiting for a train to pass.
When a message is sent across the Internet it is broken up into many small pieces called packets. Each packet is given destination and return-to-sender addresses, and sent on its way independently of all the other packets. When they all arrive at their destination, they are reassembled into the original message.
This may seem like an odd way to do things, but it’s been designed by engineers this way because of the similarities to transportation networks: if the message was sent as one big, continuous transmission it would be like the train, and everyone would have to wait while one person’s message was sent, which would be inconvenient and inefficient.
On the other hand, by breaking a message into small pieces, it’s like traveling on city roads. Sometimes traffic jams happen, but with a carefully planned route, you can travel smoothly to your destination without delay. Packets on the Internet are like this: with proper planning, messages can be sent without getting in each other’s way.
Physical Layer- Hardware
The first layer to look at, is what’s called the physical layer, the hardware layer.
At this level we are trying to connect two devices directly, and it’s hardware that makes this possible. What kinds of hardware are available? For the purposes of the Internet, hardware comes in two options: landline and wireless. There are many varieties of landline hardware, but broadly speaking they fall into two categories: copper and fiber. As for wireless, it’s based on the Electromagnetic Spectrum, and there are many varieties.
Note: I’m not sticking to any one technology because the Internet isn’t based on any specific hardware. As long as you can figure out how to send packets according to the specifications of the OSI model, it doesn’t matter what hardware you use.
Here is an inventory of some landline hardware:
Hopefully this list of hardware is helping you to be more mindful of your surroundings and all the ubiquitous technology we take for granted.
Now let’s look at an inventory of some common wireless hardware:
Data Link Layer- MAC Addresses
To introduce the data link layer, let’s return to our postal system analogy.
If you have mail for someone who lives in your community, you could use the postal system to send it, or you could just deliver it yourself. By analogy, the data link layer focuses on these levels of close transmissions.
The general term for these nearby transmissions is known as point to point. In order to make a point to point transmission, most devices use what’s called a Network Interface Card (NIC). Each card is a piece of hardware with its own “burned in” unique identifier called a Media Access Controller (MAC) Address.
Before continuing, explore the following demonstration example about how to look up the MAC addresses on your computer and other devices.
MAC Addresses Demonstration
This demonstration introduces basic but powerful Internet tools that are part of the Ubuntu operating system. Then we will learn how to lookup MAC addresses on Internet connected devices.
Requirements
In this demonstration and the ones that follow we primarily use the command line. Each operating system has its own version of the command line, but to keep things simple I have decided to stick with Ubuntu 16.04 LTS. In Ubuntu, the command line is also known as a terminal.
Note: I use a single OS because it is better to learn the concepts first, without additional complications of memorizing small operating system differences. Otherwise, this Internet theory works on the same principles regardless of the operating system. This claim is even more relevant given that at the time of writing, the most recent version of Ubuntu, 18.04 LTS, has a significantly different interface from the version shown here.
There are two main ways to interact with an operating system. The first is the graphical user interface (GUI) which is probably what you’re most familiar with: anytime you use your mouse, touchpad (or touchscreen), move the cursor, or press buttons on the screen, you’re using the operating system’s GUI.
To access the command line, open the Ubuntu desktop search tool and enter the word terminal:

This displays the Terminal icon; double-click to open. Alternatively, press Ctrl + Alt + T to open it. In either case, when you open Terminal you see the following window:
The interface opens with a prompt which, in the above example, is “~/# ” (by default the prompt is a dollar sign ‘$’, but this can be changed to a string if you prefer). Enter text commands after this prompt to converse with and instruct your operating system. To exit, close it like any other graphical window, or type “exit” and press enter.
Command lines were how people interacted with computers before GUIs. Why do we still have command lines if GUIs are newer and easier to use? There are several good reasons, but for our purposes command lines are useful because of convenient internet tools that are readily available.
Additionally, once you know how the Internet works, you will find it is often possible to interface and communicate with other computers and devices you’re connected to. Also, many devices don’t have their own GUIs, or transmitting graphical information between machines (which happens when using a graphical interface) is too slow. In either case, the command line offers a fallback interface.
Address Lookup
Before using the command line, let’s quickly look at how to lookup MAC addresses in a standard GUI.
First, open the Connection Information action at the bottom of the Networking Menu:
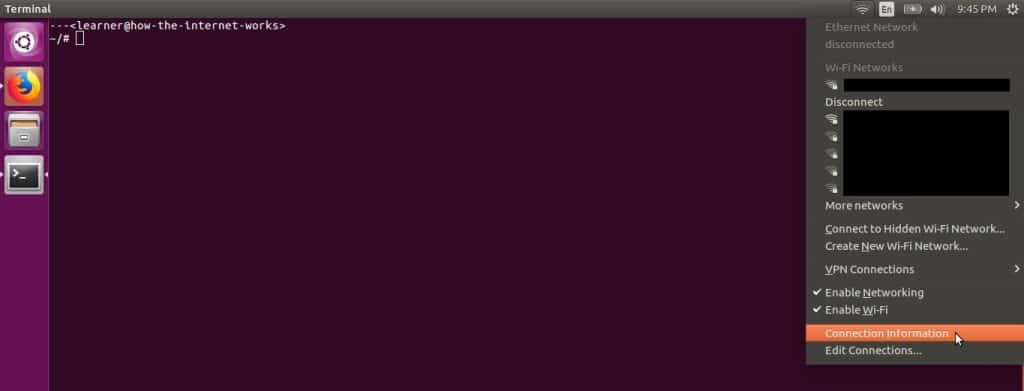
You may have noticed blacked out areas in this screenshot. For privacy reasons I have intentionally redacted, or edited, the screenshots to censor the names of LANs that were within range of my computer. Part Two delves into privacy and security matters but, for the sake of forming good habits early, I will teach these examples with the awkward redactions in place.
Getting back to MAC addresses, our Connection Information window should display as follows:
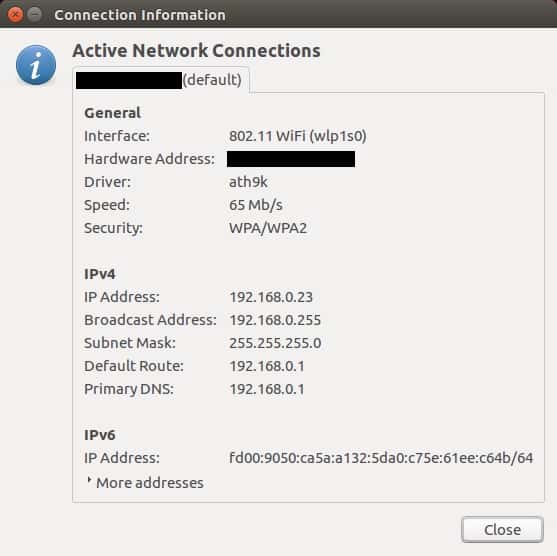
This screenshot has two redactions. The first, indicated the name of the LAN we’re connected to. The second, the value of the “Hardware Address” field, was our MAC address. I have redacted it because the MAC address associated with a given network card is permanent, and is therefore something that could be used to uniquely identify a person. It’s best to leave that kind of information out of the public view.
Since it’s been redacted, you must be wondering what a MAC address looks like. You’ll generally see them as a group of six hexadecimal numbers as follows:
01:23:45:67:89:AB
This is a fake MAC address. To see a real one open the Connection Information window on your computer. If you’re unfamiliar with the term “hexadecimal”, it simply means numbers that are represented in base 16. This is in contrast to the usual base 10 decimal numbers or even the base 2 binary numbers you may be familiar with.
How about the command line? How would we access our MAC address in the terminal?
After the prompt, type “ip link show” as follows:

and then press the Enter or Return key:

Truthfully, this looks much more complicated than the GUI approach! To find the actual address, it would be displayed where the two redactions are. The “enp2s0” version is the MAC address associated with the ethernet card, while the “wlp1s0” version is the address associated with the wireless card on my computer. Each provides its own access to the Internet and has its own distinct network card and therefore its own distinct MAC address.
As for all the extra info; the command line gives more thorough answers than the GUI. The command line has steep learning curve and can appear more complicated than the GUI, but once you learn how to use it, it can make things simpler. The reason is, it not only offers tools, it lets you build your own tools. It has its own programming language, which is something graphical interfaces don’t have.
Documentation
Learning to use the full strength of the command line is beyond the scope of this module, but let’s look at a few things; first, how to access the documentation of a command.
Above we used the ip command. There are countless commands, and most come with their own documentation called manual pages, or man pages. To access them, type man followed by the name of the command:

Which brings up a screen like this:
Wow! That’s a lot of information. It’s kind of like a dictionary: rather than read it like a book, it is a reference for the info you’re interested in. For example, with the ip command, you’d reference the options. In the above example we typed “ip link show”, but what does this mean? The man pages not only explain, they also explain every other option. Clearly ip is a powerful tool.
Don’t worry if this seems overwhelming right now. There’s no rush in mastering this toolset. You’re doing great! Let’s keep going.
LANs and Protocols
Using MAC addresses, messages are sent directly from one device to another. This means we can also create our first network, a Local Area Network (LAN). To do this we likely want to use additional hardware such as hubs, switches, and routers.
Why? Think of it like this: if you have five people talking at the same time it is difficult to hear what anyone says, and it just creates noise. But if speakers take turns, and there is someone to coordinate, things run more smoothly. Hardware such as routers help coordinate the transmissions between all these devices on a LAN.
A MAC address lets us connect and converse with another device on a LAN, but also allows us to broadcast our transmissions. When we’re communicating with one device it’s called point to point, but when we’re communicating with many devices we can send a single message to all the other devices on the network at once. That’s a broadcast.
Now that we know about point to point and broadcast, we should talk about protocols. A protocol is like a specification: a system so that engineers can maintain consistency. While specs are more about what is allowed, protocols deal more with how it is done.
As for point to point transmission protocols, engineers have come up with a few different varieties. Why? The world of engineering is strongly connected with the world of business, and sometimes things like specifications and protocols are created to compete with each other, so you end up with more than one meant to do the same thing.
So if the data link layer is about point to point and local broadcast, what are some of the protocols at this level?
For landlines there’s the ethernet protocol. Ever use ethernet cables to connect two computers? That’s also where the terminology comes from. For local wireless there’s the 802.11 protocol. If you shop for a laptop and see “802.11” mentioned, it largely just means the laptop network card and hardware adheres to the 802.11 standard.
Without going into detail, there are two other well known data link layer protocols: Bluetooth and Radio Frequency IDentification (RFID).
Data Link Problems?
Each layer has its own challenges. In this layer, the issues that arise can be summed up in a word: collision.
It’s one thing to send a message across a wire, but it gets complicated when there are many connected wires (or wireless transmissions). Collisions are what I was referring to earlier with many people speaking at once, but now we can discuss some of the actual details: let’s say you’re connected to two people but only have one receiver. What happens if both people send a message to you, and both messages arrive at your receiver at the same time? This is called a collision, because the signals (waves) combine and you can no longer distinguish each message in the resulting signal.
To make things run smoothly, engineers use what are called error detecting codes. This just means that additional information is packaged along with the message so when it is received it can be checked for errors. If an error is detected, the receiver sends back a request for a resend: “Hey, sorry, can you please say that again, I didn’t understand.”
Truthfully, you don’t need to know about error detecting codes to understand the data link layer, but I wanted to point out that engineers and designers often hide details that make their idea or product work properly, and as users we take this for granted. We are in a relationship with our technology, but we don’t know why or how.
The thing is, all the relationships around us are important, even when they’re hidden from us. For me, when I want to be in a better or healthier relationship, I talk, I communicate, I listen. In technology, we call this feedback, and it is the first step in helping us respect and understand the hidden details around us so that we can create a healthy community.
Network Layer- IP Addresses
The ping command doesn’t require us to know our own IP address (192.168.0.23), but now we know how to find it with the command line. In any case, we’re ready to give ping a try:

The ping command takes a -c option, where is the number of times you want to send the ping. In the above example I’m sending a single ping, which returns the following results:

The output says the ping was received, meaning our echo request was successful. Similar to echo request, the icmp_seq, ttl info are ICMP settings for packets. For example, ttl stands for time to live, which means that if the packet gets lost and is transmitted to (in this case) 64 devices without finding the right device, it will give up. This option is important, otherwise there would be lost packets on the internet running around in loops forever.
Other info, such as 18.862/18.862/18.862/0.000 ms, are simply statistics indicating how long the ping took. Here min/avg/max/mdev are the minimum/average/maximum/standard deviation. Since we only sent one ping, the different statistical measures tell us the same thing. If we sent many pings, they would give us more accurate descriptions which could help us understand if the network was performing well.
Note: In the above command, if the -c option is not included, the ping command pings the device forever on repeat. If you try it and see you’re stuck in an infinite loop, press Ctrl + C to break the loop.
Warning: The key combination Ctrl + C cancels the job, but it’s a bad habit to cancel other jobs this way, because in many cases it could edit important information on your computer. If you cancel this way, things are left incomplete in a way which might be hard to fix. In our case it didn’t matter because we’re not editing valuable information on our computer; we’re just looking at ping output. There are other, safer ways to cancel jobs, but that is beyond the scope of this module as it requires deeper knowledge of the command line.
Warning: Even though we’re not visiting websites, data is still downloaded when you ping devices across the Internet. If your internet connection is limited or expensive, it’s best not to ping endlessly. Also, your Internet Service Provider wouldn’t be too happy if you created unnecessary traffic that slowed down their network. There’s nothing wrong with using these command line tools, but unless you’re a qualified technician asked to test networks, it’s best to keep any tests you do simple and small.
Neighbours
Here is one last example to demonstrate the different ways you can interact with your local network. Since we’ve recently pinged 192.168.0.15, it’s still fresh in our computer’s memory, so if we run the command ip neigh:

It will show up here as well:

As it turns out, we’ve picked up two other devices on our LAN: 192.168.0.10 and 192.168.0.1. The address 192.168.0.1 is by default the private IPv4 address for the wireless router. As for 192.168.0.10? It’s just another device on my network. The redacted parts are MAC addresses. Finally, the IPv6 address (fe80::) is simply another IP address of the router itself.
Network Complications?
I have attempted to make the network layer seem straightforward, but truthfully it is very chaotic! Honestly, it is amazing to me that messages get sent across the Internet at all! Why? Let’s look at some terms that relate to the process of sending messages: broadcast routing, switching, forwarding, congestion, throttling, load shedding, Quality of Service (QoS), traffic shaping, and leaky buckets.
It’s “simple” enough to send a message: break it into packets, and give each the destination IP address. Then broadcast the packet to other devices nearby. Once a device receives the packet, it looks at the IP address and asks: is this packet for this destination? If not, it is forwarded, and on it goes. Sometimes a router receives the packet and asks: is the destination even on this network? If not, the packet switches networks and continues on, eventually arriving at the correct destination. Once the packets arrive, the message is reassembled and delivered to the final user.
And that’s the simple part! What’s not so simple are the Quality of Service expectations of users. Sometimes QoS expectations are lax: people don’t have extreme expectations for their emails to arrive instantly, for example. Other times QoS expectations can be very high, for instance, for gamers interacting in real-time, or users on a conference call that needs to be clear and happen without delays, stalls, or freezing.
There are many instances in which users demand a high QoS, but with so many people using the Internet simultaneously,coordination is a challenge we take for granted. Think about all the packets flying around endlessly that enable everyone to communicate over this shared infrastructure – all the memes, pics, videos, emails, blogs, etc. – it’s dizzying to think about.
An analogy can be drawn between this aspect of the Internet and traffic jams on a road network. The difference is that engineers have a few tricks to mitigate the complexity, such as the leaky bucket algorithm.
As for congestion, not only engineers, but ISPs do their part too. Sometimes ISPs throttle their own networks and reshape traffic to keep it in balance. Sometimes though, routers and other message passing hardware simply drop packets altogether. Devices that understand Internet Protocols are programmed to negotiate as fairly as possible, but there are no promises.
This brings us to the next layer, the Transport Layer, which works to smooth out these rough edges.
Transport Layer- Connections
At this point, our postal analogy is reaching its limit, but I think we can manage one or two more comparisons. To start, most postal services offer some sort of express service. The transport layer is kind of like that, in that it offers a dedicated service just for you.
It’s one thing for devices to send a few packets to each other once, but if they know in advance they would like to have a long meaningful conversation – and, given the messiness of the network layer – it makes sense for them to commit to an express or dedicated service. This way they can focus on each other with fewer distractions.
In the transport layer there are two main protocols, the Transmission Control Protocol (TCP) and the User Datagram Protocol (UDP). The TCP defines the connections: when devices first contact each other looking to make a connection this is called a connection establishment. When their conversation winds down and it’s time for them to say their goodbyes it’s called a connection release.
The difference between the two protocols is that TCP is focused on a perfect and complete communication, while UDP is more concerned with getting as many packets to the destination as quickly as possible. With TCP no packets are lost and everything arrives in order. With UDP some packets might be lost, and although it’s ideal that the packets arrive in order it’s not absolutely necessary.
In the literature you will often see these written TCP/IP and UDP/IP, which simply means these protocols are built on top of the Internet Protocol (IP); but given our layer cake (stratification) approach to transmissions this is expected.
Establishing a connection in TCP is actually quite tedious because everything has to be perfect. Under this protocol, the devices trying to communicate have to reassure each other a lot. There’s an old joke about this:
Hi, I’d like to hear a TCP joke.
Hello, would you like to hear a TCP joke?
Yes, I’d like to hear a TCP joke.
OK, I’ll tell you a TCP joke.
Ok, I will hear a TCP joke.
Are you ready to hear a TCP joke?
Yes, I am ready to hear a TCP joke.
Ok, I am about to send the TCP joke.
It will last 10 seconds, it has two characters,
it does not have a setting, it ends with a punchline.
Ok, I am ready to get your TCP joke that will last
10 seconds, has two characters, does not have
an explicit setting, and ends with a punchline.
I’m sorry, your connection has timed out. …
Hello, would you like to hear a TCP joke?
(Source)
As you can see, in order to ensure a perfect conversation there are many error correcting reassurances. If you study the non-joke version of the protocol, you’ll see a lot of error correcting strategies in detail.
As for UDP, it’s more useful for live streaming and real-time gaming. Continuity of a live stream or game is important; some info is vital and can’t be interrupted, but losing a random video frame every once in a while doesn’t generally have a negative effect on user experience. By the way, there’s a UDP joke as well:
Hi, would you like to hear a UDP joke?
Yes, I would like to hear a UDP joke.
To get to the other side.
…
Why did the chicken cross the road?
(Source)
If you do computer programming that involves communicating with websites you might run into the term sockets. They are a standard programming interface used to establish and release transport layer connections. They are actually considered low-level and many code libraries have more convenient tools, but they’re still worth knowing about, as these higher-level tools are primarily built upon sockets.
Transport Issues?
For the transport layer and beyond, the engineering issues are the same as what has been discussed. There can be other problems, of course, but the main ideas are similar to the previous layers. In any case, as with the network layer, the transport layer handles flow and congestion behind the scenes. If you investigate protocol specifics, there are further strategies and algorithms dealing with such things.
Session Layer- Conversations
The session layer in a lot of ways is an extension of the TCP protocol, where you’re looking to have a more committed, engaging, involved conversation between devices. It looks to establish expectations for a session. Truth be told, many users and applications online don’t actually use this layer, but it is good to be aware of.
There’s not much else to introduce in terms of new ideas here. It’s more a matter of technical details so we’ll continue on to the next layer.
Presentation Layer- Formatting
The presentation layer exists to solve a problem with transmissions we haven’t discussed: translation. What if you sent mail to another country where they spoke a different language? Would they be able to read the destination address you put on the envelope?
This concern arises with computer systems too. Different computers might use a different way to encode their information. When you send your message to another computer will it understand? It could have a different operating system, or the software that lets the computers connect to the Internet (and each other) may have been coded in a different programming language.
Presentation Concerns?
Truthfully, the presentation layer is a rather fuzzy concept. Software in the application layer (which comes next) often knows how to translate and format encodings and so does the job of software in the presentation layer. Devices are adept at keeping the layers separate, but there are areas and internet tasks where they overlap.
This brings up an important point about all these engineering protocols: they’re not perfect. They are rules made by humans meant to help achieve goals. If the rules are helpful, they will be followed strictly, if not then they might not be. On the other hand, if you absolutely need these rules to be followed then you make them binding, for example you could get lawyers involved to make them legal. Otherwise, protocols really are just informal agreements between engineers.
This is a profound idea actually, so let’s linger: when people speak the same language they agree to a shared meaning because it’s useful, but they don’t have to. People could speak a private language that only a few other people knew. Similarly, a device doesn’t have to use TCP/IP to communicate, but if it wants to speak to other devices on the Internet it generally will. Then again, as this presentation layer points out, devices can cheat the rules a little as long as it doesn’t confuse other devices.
Should they cheat the rules? This is a question of the spirit and intent and the letter of the law. When you become a sufficiently experienced designer you learn which rules can be bent, which can be broken, and which absolutely can not. As to which protocols are immutable, flexible, or breakable, is a debate beyond the scope of this module.
Application Layer- Interface
The application layer is the final layer in this model, and it focuses more on users of the Internet, be they human users or application software. In turn, this layer tends to be much more focused on human oriented design.
Human Users
This layer is less about technical details and more about making it convenient for people to navigate the world wide web. IP addresses are great, but users are unlikely to memorize addresses of random numbers for websites they visit.
The application layer introduces a new type of address called a Uniform Resource Locator (URL). Here’s an example of a URL address you might know:
Nice site! How do URLs work though? How can we use them to send transmissions across the Internet?
Since URLs are meant to be read by people, we still use IP addresses the way we did before, but now we associate each URL with an IP address. There are special devices called DNS servers that are always online and dedicated to keeping records of which URL address maps to which IP address. When you use a URL to access a destination device, you first contact one of these DNS servers and it tells you the IP address. Then you make transmissions as you did before.
This strategy for URL resolution is called the Domain Name System (DNS).
Limitations?
URLs are nice, but how do you get one? How do you get the right one?
It’s easy for hardware companies to produce IP and MAC addresses, for example, as they’re just numbers; and users don’t care what the numbered address is as long as they can connect online. But, when addresses can be words or phrases which humans find meaningful (such as Pinnguaq), all of a sudden people care about what address they get and there is demand and competition for certain favourable URL names. How does a hardware company arrange for the right person to get the right address?
In the case of URLs, it isn’t hardware companies that assign these addresses. There are international organizations which, for a small fee, let you register what are called domain names. You have rights to a domain name for a period of time, and it forms the basis of your URL names and addresses. More details are given in the demonstration at the end of this section.
The other limitation to consider is that it’s hard for DNS servers to keep such a large list of URL-to-IP address bindings updated and accurate. There’s a lot of fancy math and engineering strategies used to keep the DNS working so that devices can find other devices, and people can find other people.
Application Software
It makes sense that humans are using the Internet, but what about application software?
Yup. Our computers usually have programs running in the background called daemons which perform tasks for us, such as checking for software updates, security patches, updating our mobile GPS location, not to mention dedicated software that scrapes websites to catalogue them (search engines do this). Even human users don’t connect directly with the Internet, we generally use web browsers.
Ports
If there are many different applications on the same machine and connecting to the Internet at the same time, how is this coordinated? This is the idea behind the next type of address called a port. Unlike MAC, IP, or URL addresses, port addresses aren’t unique to a user or application. Think of them more like an office mailbox, or a school locker. You are assigned that location temporarily, but not permanently.
At the same time, in the application layer, certain protocols and services are so common they are assigned specific ports by convention. For example, the Hypertext Transfer Protocol (HTTP) is an application layer protocol which lets us specifically transmit web pages, and is typically assigned port 80. This means web browsers or other applications which use HTTP listen for their respective packets on this port.
Protocols
Besides HTTP, what other application layer protocols are there?
Internet Message Access Protocol (IMAP) is used for email. Originally email was just text without attachments. Then users wanted to add attachments, so email protocols were extended with Multipurpose Internet Mail Extensions (MIME) to allow for this.
The Dynamic Host Configuration Protocol (DHCP) allows a device on a given network to assign and re-assign IP addresses to other devices on that network. It might seem intuitive to include DHCP within the network layer, but DHCP makes use of port addresses, so technically it fits better in the application layer.
Complexities?
First of all, there is the issue of privacy. For example, the HTTP protocol transmits webpage packets without any built-in security. Website content is transmitted such that anyone can view it. If you send a password to a website, people can see your password; or if you’re browsing a site, people can see what you’re looking at. This raises privacy and security concerns.
The solution to this is HTTPS, where the ‘S’ stands for Secure. In this protocol extension, HTTP content is encrypted before it’s sent and decrypted at its destination. Even if HTTP packets are intercepted the content is not visible.
Beyond this, other complexities arise from the great diversity of applications online, which creates a variety of communications relationships. Many of these relationships share common patterns which help define relationship types. This allows developers and engineers to better design and plan for smoother Internet use.
Clients and Servers
The client-server model is a relationship between devices, where the server has content the client is interested in. This is to say, the client requests information from the server.
For example, web browsers are clients because they request to see web pages. Any device which serves these web pages when requested is a server. A laptop could be a server if it has the correct software. At the other end of the spectrum, a big business site with high traffic requires industrial grade hardware to serve the millions or billions of client requests. In this case, the hardware used is also a server.
Another example is a DHCP server. A client device requests an IP address so it can join the network, and if possible the server replies with an available address.
Technology Stacks
Many human-oriented web applications such as web pages and websites can become so complex they require entire technology stacks of their own. For example, the HTTP protocol allows us to transmit web pages, but web pages themselves are designed and written using the HTML/CSS/Javascript technology stack.
For any webpage this begins with the content. Hypertext Markup Language (HTML) is then used to declare semantic relationships within this content, which simply means how you want the content designed. Cascading Style Sheets (CSS) take that hypertext markup and explains how you want it presented. When a web browser looks at the page, it reads this CSS information and tries to present it the way you described. Finally Javascript, a programming language, lets you explain the logic of your webpage content. This has the strongest use when you want your page to be interactive.
Vendor Models
With all the designs and relationships the web is built on, we end up with many specifications and protocols. It’s one thing to specify how something should be, but who actually implements these designs? That’s the idea behind a vendor. When it comes to Internet technology, vendors are businesses who publicly announce that they will implement certain specifications, and that it’s worth using their product because they are reliable. To support their claims, vendors document how much of a given spec they currently support, which is called compatibility.
For example, a web browser looks at the CSS description of a web page, but who is in charge of the browser itself? There are various competing browsers; each a product of its respective vendor. For example Firefox is a browser, while the Mozilla Foundation is its vendor.
Why use the vendor model? Businesses are focused on growth, but the pace at which engineering specs and protocols mature and stabilize is often too slow. The vendor model is a compromise which offers some flexibility because vendors aren’t required to maintain full spec compatibility to release their product. At the same time, by documenting what parts of the spec they currently support, they allow for a level of engineering stability.
We covered a lot of new information in this section about the application layer. Take some time to explore the ideas in the related demonstration.
Port And URL Addresses Demonstration
In this demonstration we will introduce the basics of ports, URLs, and domain names. We will use them to further explore some of the concepts from the application layer as well as the transport layer. In the process we will look at the traceroute, ping, whois, ssh, and scp commands.
Ports
This demonstration focuses primarily on URLs, but briefly touches on ports and how they can be referenced. If you’re using a Linux OS, such as Ubuntu, you should be able to find the following text file:

It provides a list of protocols and their associated ports, located at /etc/services on the filesystem. A copy of that file is also included in the asset folder.
URLs
The standard approach to entering a URL address is by typing it into your web browser, for example:

Here the URL is https://pinnguaq.com. The domain name is simply pinnguaq.com, and the remaining part of the url (https://) indicates what application layer protocol is being used for the transmission. In addition to basic URLs, there are more complicated ones, such as:
Here the component /makerspace/ tells the web server that we want a subpage, the Makerspace page.
There are even more complicated URLs, but the components associated with them have more complex names only to provide additional information for the web server’s benefit.
Traceroute
Let’s explore the traceroute command. In a previous demonstration we successfully pinged a device. Traceroute is similar, except more thorough: at every ‘hop’ along the way the address is sent back, allowing us to trace the route of our packet.
Installing traceroute is easy enough:

Running it is just as straightforward. Let’s follow the path taken to our pinnguaq website:

There’s a lot of information, and a few points to mention here.
First of all, you’ll notice there are no redactions. In previous examples any information that could be used to identify me or my physical location were redacted, but here I’ve made an exception. The reason is I’m using the network at the University of Alberta which only tells you that I am in Edmonton, Alberta. This is non-specific information that is publicly available anyway, so I am not concerned.
Next, what surprised me about the route is that my packet passed through yeg, yyc, yvr. These are airport designations also used as alternative names to identify cities. YEG is Edmonton, YYC is Calgary, and YVR is Vancouver. Wow, my packet has travelled more than I have this year!
The other point is how many devices, computers, and servers an communication connects with online. Data analysis is a typical business practice: as you interact with websites (reading, shopping, researching, engaging with online communities, etc.), companies often read the pages you connect with to understand how you interact online.
For their purposes, businesses send the information they gather to their databases to build a profile of you. This allows them to target their advertisements to you, and recommend additional products you may be interested in. Whether or not this is an acceptable thing for them to do is another matter, which is explored in Part Two. Either way, it’s good to be aware of.
URL to IP
Another thing traceroute tells us is the IP address for pinnguaq.com, which is 146.66.66.8. If we want to convert a URL to its IP the ping command would be more direct:

Previously when using ping we entered IP addresses directly, but you can also enter URLs. The result is similar to those pings except here we’re also told the IP address:
DuckDuckGo
Since we can enter URLs into web browsers, and they’re largely interchangeable with IP addresses, can we also enter IPs into our browsers?
The short answer is yes, but it’s slightly more complicated than that. For example, let’s try it with duckduckgo.com. Duck Duck Go is a search engine similar to Google. But unlike Google, it doesn’t track the searches you make, which means it doesn’t build an online profile of you.
In any case, if you ping duckduckgo you can retrieve its IP address. I got 50.18.200.106, is it the same for you? Large Internet companies get such a high volume of traffic it makes sense to have more than one server to divide the load, which also means they will have more than one IP address. When you connect to their site you’re likely connecting to the server closest to you.
Let’s put the IP address in our browser’s address bar:

When I connect this way it brings up the main page:

This is an example where it does work, but entering IP addresses in this way doesn’t always work. For example, the IP address for pinnguaq.com doesn’t work (at the time of writing). There could be a number of reasons. Perhaps the server that hosts the pinnguaq pages is configured to deny connection requests using IP addresses, or the server may not be configured properly. It’s hard to say without further inspection.
Domain Names
Domain names make up the part of a URL which most closely corresponds to an IP address. But why? And how? The rest of the information in a URL name is usually meant for the server being contacted, but the domain name itself is generally what the DNS servers lookup and translate into IP addresses.
If this is the case, how does one go about obtaining a domain name? As mentioned earlier, there are international organizations in charge of name registration. If you’d like to learn more about these international organizations, you can visit their websites, notably ICANN, as well as IANA.
To register a domain name with these organizations, a small fee is required. These organizations aren’t interested in profit pre se; it’s more about administration fees. But there are businesses and users who buy up these domain names and resell or lease them to their customers for profit. Keep this in mind if you’re looking to obtain a domain name.
Whois
Now that we’re starting to get our bearings with this application layer content, let’s see what else we can do!
If you’d like to learn more about the person or corporation that currently holds a domain name, there’s a simple command line tool for this. The whois command isn’t typically preinstalled on Ubuntu, so will have to be installed:

Otherwise it’s quite straightforward to use:

Some of this information might be useful, some might not be. It can be helpful if you’re looking to follow ownership or see when a registration is expected to expire, for example.
Secure Shell
The terminal we’ve been using is also sometimes called the shell. As mentioned previously, one advantage of the command line compared with GUIs is it allows us to more readily interface with other computers using the shell. Instead of the regular shell though, we need to use the secure shell (ssh) command:

The difference between ssh and the regular shell (sh), is that ssh encrypts the commands and transmissions sent to other devices. This is a security feature, necessary because the content of unencrypted packets could be viewed, or worse, the packets could be intercepted and their content changed by a user pretending to be you. Without these security features, how would the device on the other side know it wasn’t you?
If you connect with another device using ssh, it will first ask if you recognize the device you’re trying to connect with. Cryptography is beyond the scope of this module, but think of it as another type of address. The assumption is you’re able to recognize this encryption address so that you know you’re connecting with the correct device. After that, you’ll be asked to log in the way you would for any other computer (and would need an account already set up on that machine).
Secure Copy
The secure shell command lets us log in to a remote device over the Internet. This has endless possibilities in its applications. What if we want to copy a file from one computer to the other? That’s what the secure copy (scp) command is for:

Here, I’m telling the command line to copy the folder named photos on my computer to a user on a remote machine with IP address 192.168.0.15, and put it in their Pictures folder. Similar to ssh, the command line has a regular copy (cp) command for use with your computer’s filesystem. This scp version encrypts the file(s) being sent so that other users can’t eavesdrop.
Warning: The command line is a powerful tool, which should be used with great care if you’re creating, moving, or deleting files and folders. Until now, we’ve used the command line to look up information, which is generally safe to do, but be cautious when you’re modifying information.
In this regard, the advantage of a GUI is its user friendly features: if you move something to the trash, it will ask if you want to delete it, or if you move a file into a folder and there’s another file already there with the same name, it will ask if you want to replace it. The command line doesn’t have these redundancies or warnings. If you tell the shell to delete something, it will delete it immediately. Gone! If you tell it to copy something and there’s a file with the same name, it won’t warn you about it, it will simply replace it.
Until you have proper training, it’s better to use the GUI if you want to change information on your computer or its filesystem.
Connection Problems?
If you’re looking to try out ssh, there are two major things which may prevent you from connecting.
The first is that ssh follows the client server model. Ubuntu usually has the client version installed by default, but if you – as the client – want to ssh into another computer, that computer will need to have the server version installed:

The second issue that might prevent a connection is the firewall. The secure shell application is serviced on port 22, meaning the server version listens for ssh requests at that port. Your firewall might be preventing this. If you want to quickly look this up on the command line you can use uncomplicated firewall (ufw):

Check the man pages for ufw documentation. You can choose to allow or deny packets if they’re sent to specific ports.
Warning: If you are still unable to make a connection, general troubleshooting can be tricky. The technology of the Internet is built on many other technologies being configured properly, so you need patience when diagnosing a problem. Ask a friend in your community who knows about this stuff, otherwise there’s always the Ubuntu help pages.
Final Thoughts
I use ssh and scp all the time. For example, I have a laptop whose keyboard stopped working. Everything else on the laptop works fine though, so when I need to use a keyboard, instead of using a virtual keyboard or plugging in a usb keyboard, I just ssh in from the newer laptop I bought as its replacement. It’s very convenient and satisfying.
To summarize the major ideas presented here we will play an empathy game: imagine us as a message being transmitted across the Internet.
To be a message, we would split ourselves up, and each piece of us would be wrapped in layers of addresses and protocols, and when we were finally ready for our journey we’d set off. Along the way we would see many places. Occasionally we would even switch over to different realms. Finally though, after many adventures and even some hardships, we would arrive at our destination. At this point we’d be unwrapped and made whole again.
Travelling through layers indeed! Makes me wonder how the Angakkuit of old did it?
As a final thought, we now have a basic understanding about how to connect to other people on massive scales and over long distances, and this is a great power. And with this power comes responsibility: ethics. The Internet is an invaluable resource, but can it teach us how to interact with others in good and healthy ways? Let’s explore this in Part Two.
Pijariiqpunga
Resources
- A New Way to look at Networking [Video/1:21:15]: Van Jacobson gives a thorough history and comparison of the Internet to the telephone communications system and offers future directions for the Internet.
- Computer Networks, 5th Edition, Andrew S. Tanenbaum, Vrije University, Amsterdam, The Netherlands. This book has served as the major source of my own Internet education. It is thorough, but still manages to balance technical detail with readability.
You might also like

Building Healthy Relationships Online
The internet can be a complicated and scary space. Learn how to build healthy relationships with others while you navigate the web!

Cultural Sensitivity When Posting Online
Memes can be funny to share with friends and family. But sometimes they are offensive to other cultures. Learn what not to share online and cultural sensitivity.

Critical Literacy Scams
It is important for anybody to know how to not become subjects to online scams. Learn how to develop the required skills to avoid scams online.

